Introduction
Hadoop actually offers a lot of ways to execute and utilize the MapReduce “magic”. MapReduce tasks (the correct terminology is Application; this means every MapReduce task is called an Application) can be written in many different programming languages. In addition there are a lot of Hadoop-related projects available which unleashes parts of MapReduce “magic” even without the need of any programming (e.g. Hive in combination with HiveQL). However as the goal of my blog is to keep articles simple but informative I’ll focus on a single approach only. This time I’ll show you how to achieve MapReduce with help of a simple Java program. Please note that you will need an up and running Hadoop setup for the upcoming walkthrough-chapter. During the walkthrough you will learn the following:
- some command line features to manage and explore the HDFS-filesystem
- how to explore the HDFS-filesystem in namenode web application
- how to implement a simple word count MapReduce task
- how to execute the implemented MapReduce task
Walkthrough
The goal of this chapter is to use MapReduce to count the chickens in this text snippet:
chicken chicken correct horse battery staple chicken chicken chicken chicken chicken chicken chicken chicken chicken chicken chicken chicken
No need to count them manually. Feel free to do so anyway 😉 As there are only 14 of them it’s easy. However imagine we have a text file containing hundred thousand or more, I guess in this case you would be happy about MapReduce :). Here we go : )
1) Copy & paste the “Chicken” text snippet mentioned above to a text file you place in /home/hadoop/chickens.txt
2) Copy the chickens to HDFS-filessystem:
hadoop@roadrunner:~$ hadoop fs -copyFromLocal file:///home/hadoop/chickens.txt hdfs://localhost:9000/
3.1) Check copy success with help of command line:
hadoop@roadrunner:~$ hadoop fs -ls hdfs://localhost:9000/ Found 1 items -rw-r--r-- 1 hadoop supergroup 674 2016-01-30 15:26 hdfs://localhost:9000/chickens.txt hadoop@roadrunner:~$
3.2) Check copy success with help of namenode web application:
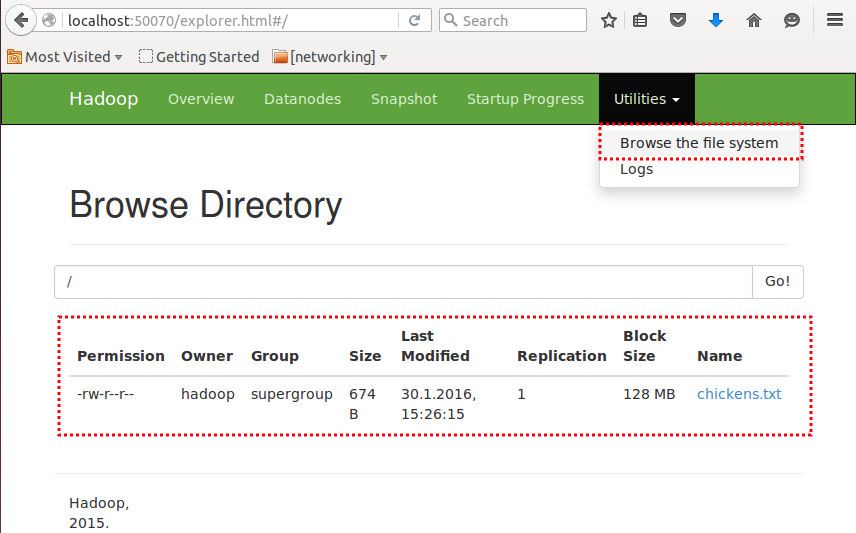
4) Create a directory we use as general storage location for MapReduce tasks
hadoop@roadrunner:~$ mkdir mapreduce-tasks
5) Implement the “chicken count MapReduce task” and compile the source code afterwards
Please note:The implementation in this article is based on a Maven-project. How to install Maven, the project structure it requires and how the project is built afterwards is not covered by this article. The whole project contains two files: ChickenCount.java and the pom.xml needed by Maven.
The implementation of the “chicken count MapReduce task”:
package com.eden33.hadoop.task;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
/**
* @author edi
*/
public class ChickenCount {
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private final Text word = new Text();
private final Text chicken = new Text("chicken");
@Override
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
if(word.equals(chicken)) {
output.collect(word, one);
}
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(ChickenCount.class);
conf.setJobName("chickenCount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
The pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.eden33.hadoop.task</groupId>
<artifactId>com.eden33.hadoop.task.wordcount</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<haddop.version>2.7.1</haddop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${haddop.version}</version>
</dependency>
</dependencies>
</project>
6) Copy the compiled jar to the directory created in 4). My jar file compiled with Maven:
hadoop@roadrunner:~/mapreduce-tasks$ ls -lah total 16K drwxrwxr-x 2 hadoop hadoop 4,0K Feb 13 12:05 . drwxr-xr-x 14 hadoop hadoop 4,0K Feb 13 11:22 .. -rw-rw-r-- 1 hadoop hadoop 5,3K Feb 13 12:05 com.eden33.hadoop.task.wordcount-1.0-SNAPSHOT.jar hadoop@roadrunner:~/mapreduce-tasks$
7) Create a directory we use as general storage location for MapReduce task results
Please note: I now create a storage location on my local file-system. However the storage location for results is not limited to this. Another option would be to choose the hdfs file-system.
hadoop@roadrunner:~/mapreduce-tasks$ mkdir /home/hadoop/mapreduce-results
8) Execute the “chicken count MapReduce task”:
hadoop@roadrunner:~/mapreduce-tasks$ hadoop jar com.eden33.hadoop.task.wordcount-1.0-SNAPSHOT.jar com.eden33.hadoop.task.ChickenCount hdfs://localhost:9000/chickens.txt file:///home/hadoop/mapreduce-results/1/ 16/02/13 12:26:30 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 16/02/13 12:26:32 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 16/02/13 12:26:33 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 16/02/13 12:26:34 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 16/02/13 12:26:36 INFO mapred.FileInputFormat: Total input paths to process : 1 16/02/13 12:26:37 INFO mapreduce.JobSubmitter: number of splits:2 16/02/13 12:26:38 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1455357938720_0001 16/02/13 12:26:40 INFO impl.YarnClientImpl: Submitted application application_1455357938720_0001 16/02/13 12:26:40 INFO mapreduce.Job: The url to track the job: http://roadrunner:8088/proxy/application_1455357938720_0001/ 16/02/13 12:26:40 INFO mapreduce.Job: Running job: job_1455357938720_0001 16/02/13 12:27:10 INFO mapreduce.Job: Job job_1455357938720_0001 running in uber mode : false 16/02/13 12:27:10 INFO mapreduce.Job: map 0% reduce 0% 16/02/13 12:28:03 INFO mapreduce.Job: map 50% reduce 0% 16/02/13 12:28:15 INFO mapreduce.Job: map 100% reduce 0% 16/02/13 12:29:31 INFO mapreduce.Job: map 100% reduce 100% 16/02/13 12:29:38 INFO mapreduce.Job: Job job_1455357938720_0001 completed successfully
9) Check the MapReduce result directory we have provided while execution in 8)
hadoop@roadrunner:~/mapreduce-tasks$ vi /home/hadoop/mapreduce-results/1/ part-00000 .part-00000.crc _SUCCESS ._SUCCESS.crc hadoop@roadrunner:~/mapreduce-tasks$ vi /home/hadoop/mapreduce-results/1/part-00000
Summary
/home/hadoop/mapreduce-results/1/part-00000 was created and contains the result text “chicken 14” if you followed my walkthrough with success. In addition you may want to check the YARN resourcemanager web application mentioned in my previous article about Hadoop setup. You will notice that it provides additional basic information about submitted tasks (e.g. start time, end time and the task status). Congratulations; no need to count the chickens manually anymore 😉 Code is available on Github.